DockerでOllamaとDifyを連携してローカルLLM環境を作る(手順編)
よく見かけるローカルLLM環境は、OllamaをホストPCに直接導入し、DifyをDocker環境に導入する構成ではないでしょうか。せっかくDockerを使っているので、OllamaもDocker環境に導入したところ、連携にひと手間必要でした。その経験を共有いたします。今回は手順のみを記載し、解説は次回とします。
前提
- Windows 11 Home バージョン24H2
- GPUは搭載無しのCPUのみで稼働
- Windows版Docker Desktopが導入済み
- git導入済み
- 今回例のDifyはポート80を利用(すでにローカル環境でポート80ご利用の場合DifyのHTTPサーバーが起動しません)
- Windowsターミナルやコマンドプロンプトなどマウス以外の操作をした事がある方向けの内容
DifyをDockerで導入
導入手順のオリジナルはhttps://docs.dify.ai/ja-jp/getting-started/install-self-hosted/docker-composeです。
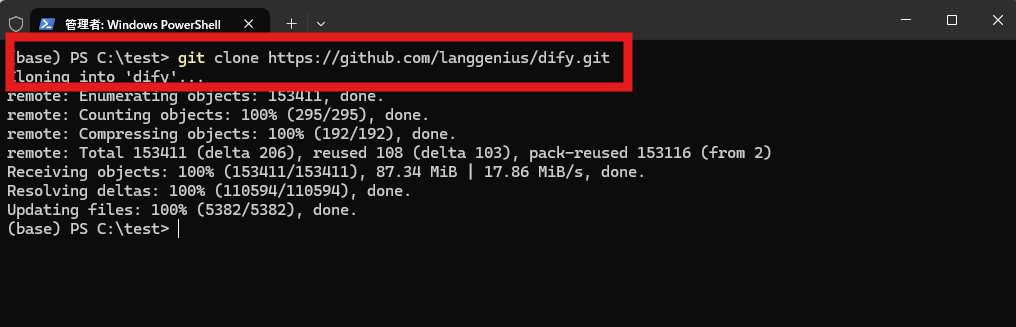
Windows版Docker Desktopを起動後ターミナル画面からgit clone https://github.com/langgenius/dify.gitを実行
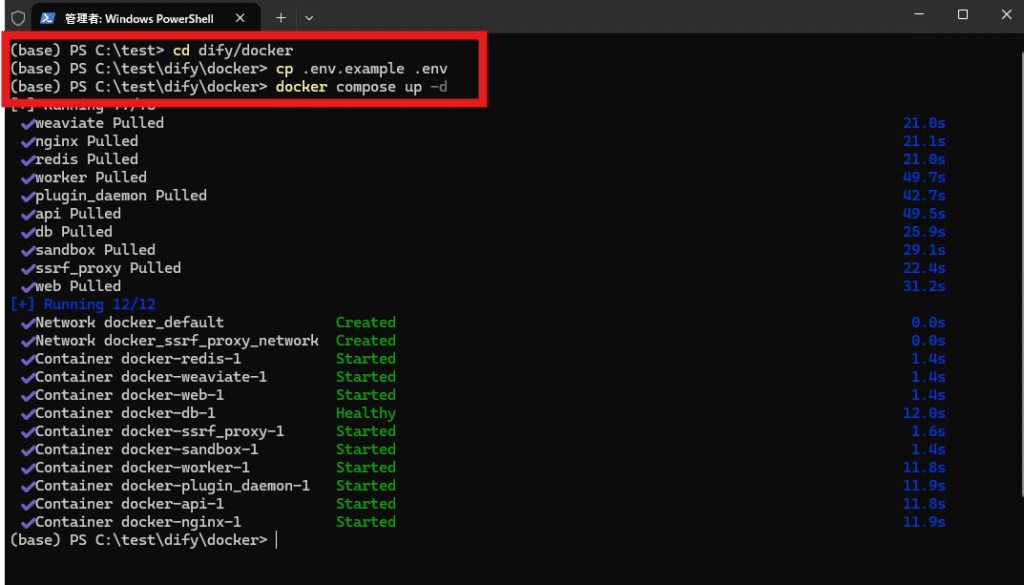
cd dify/docker
cp .env.example .env
docker compose up -d
の順にコマンドを実行すると上図のようにDifyを構成するコンテナ(仮想マシン)が作成されます。
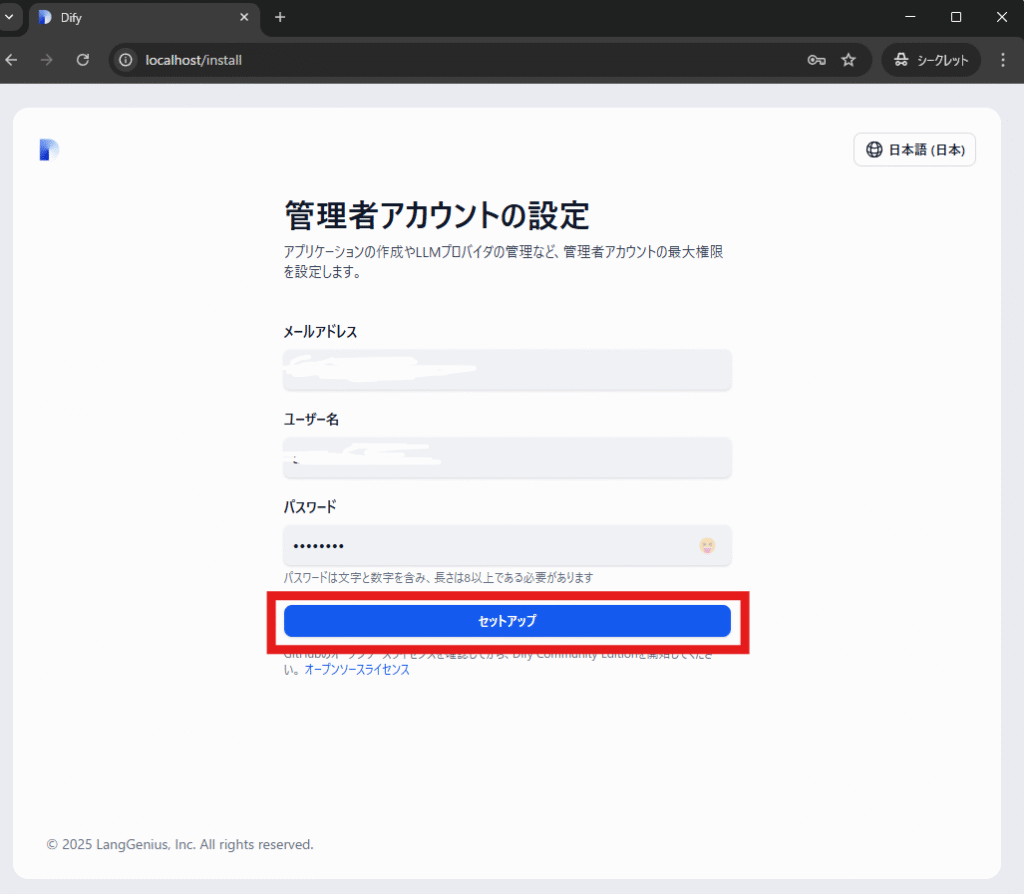
上図のようにブラウザURLにlocalhostを指定し、「管理者アカウントの設定」画面ではメールアドレス、管理者として作成したいユーザー名とパスワードを入力後「セットアップ」をクリックします。
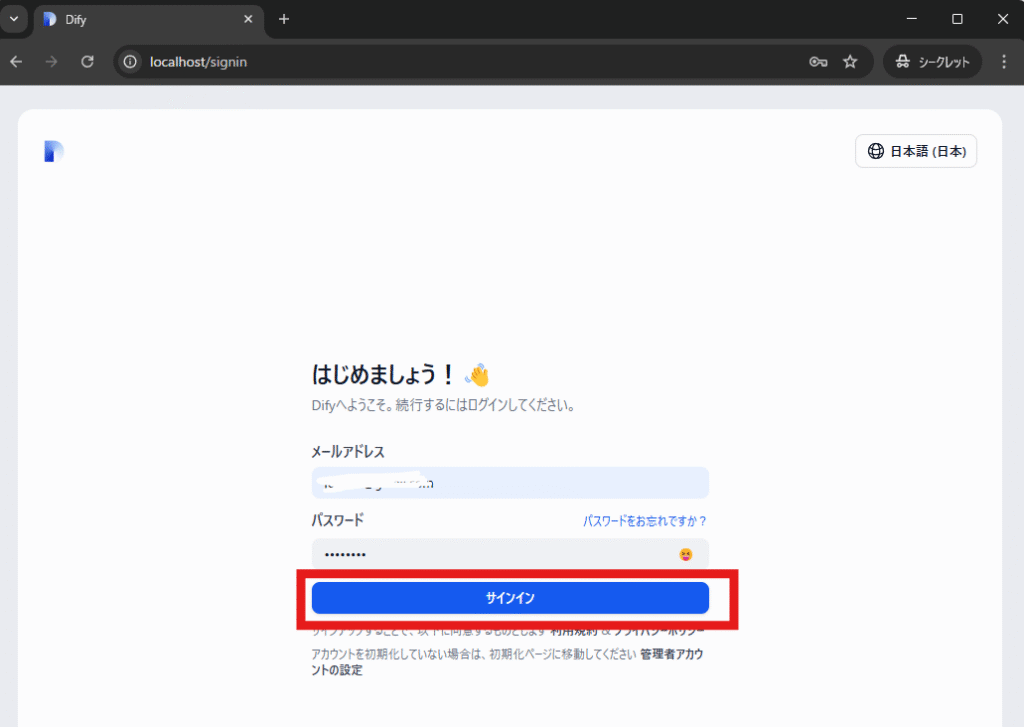
先ほど設定したメールアドレスと管理者パスワードを入力し「サインイン」をクリックします。
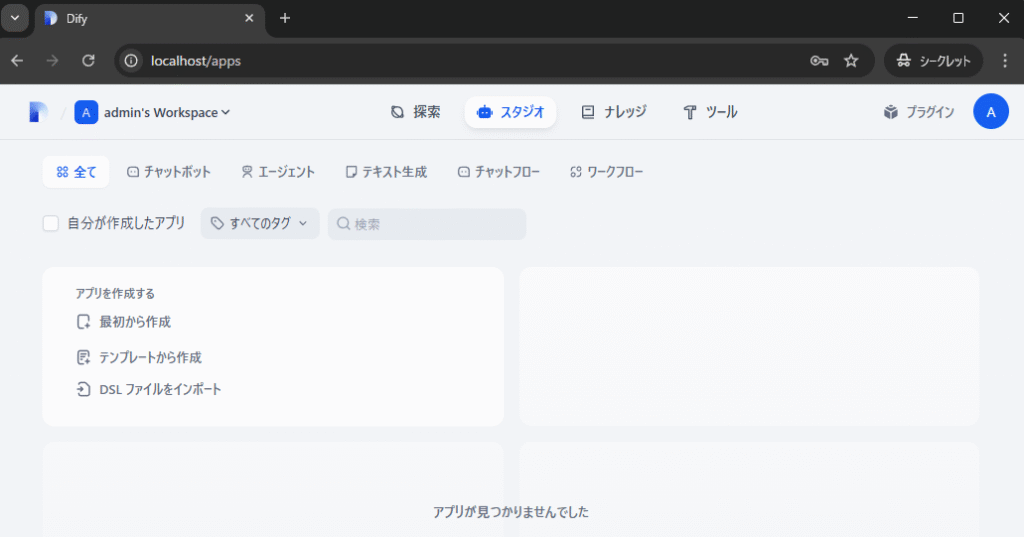
上図のようにDifyが使えるようになりました。
OllamaをDockerで導入
Ollama導入手順のオリジナルはhttps://hub.docker.com/r/ollama/ollamaです。
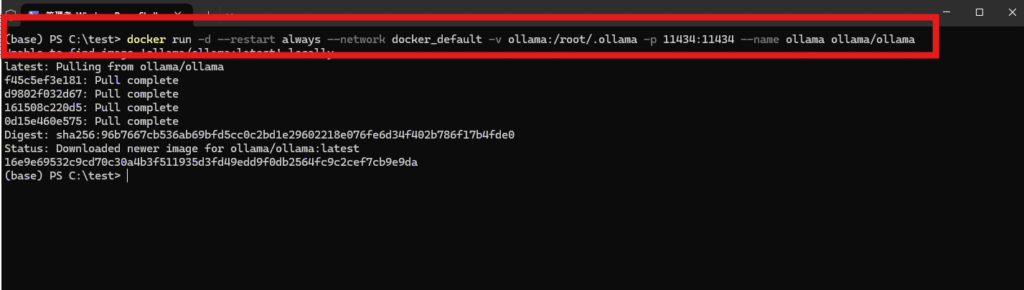
上図のようにターミナルから
docker run -d --restart always --network docker_default -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
を実行します。
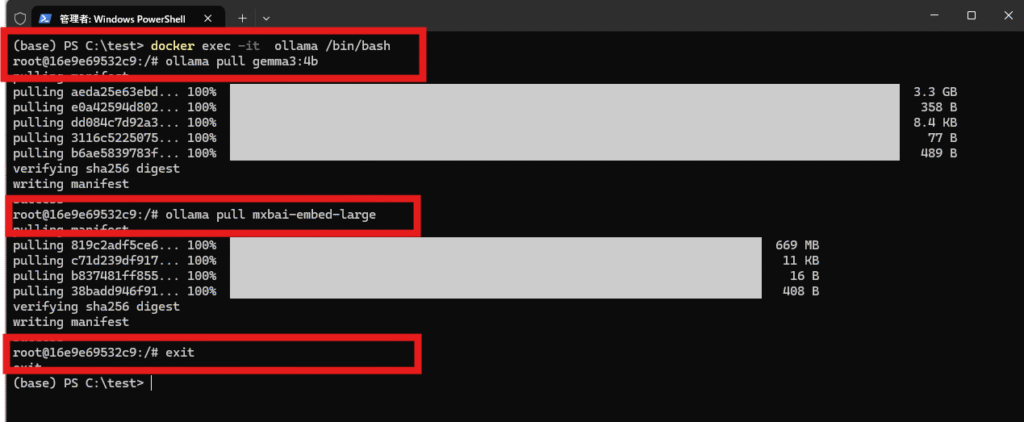
OllamaにDifyで使うLLMモデルとしてGemma3、Difyのナレッジ(いわゆるRAG)作成に使う埋め込みモデルとしてmxbai-embed-largeを導入するため以下コマンドをターミナルから実行します。
docker exec -it ollama /bin/bash
ollama pull gemma3:4b
ollama pull mxbai-embed-large
exit
DifyからOllamaと連携
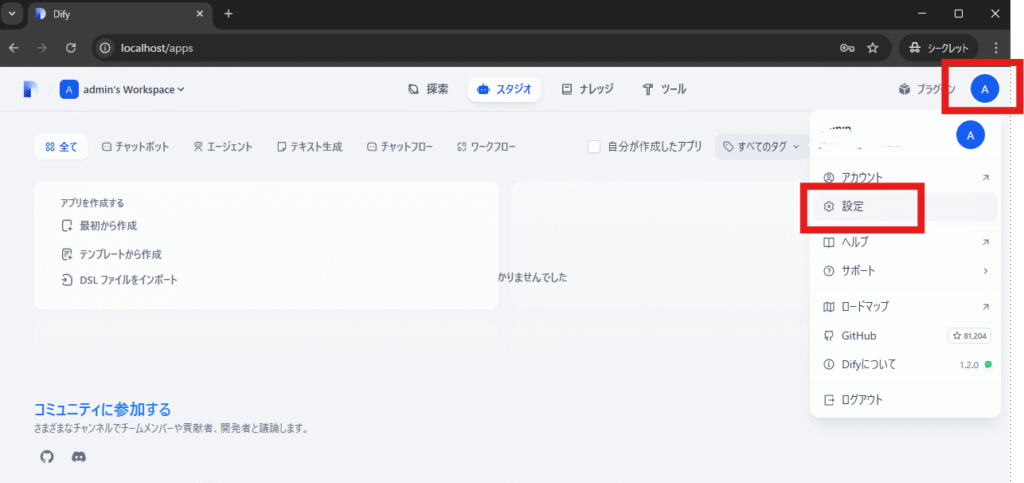
Difyに管理者でログイン後、管理者アイコン-->「設定」の順にクリックします。

「モデルプロバイダー」をクリック後、モデルプロバイダーからOllamaを探し「インストール」の順にクリックします。
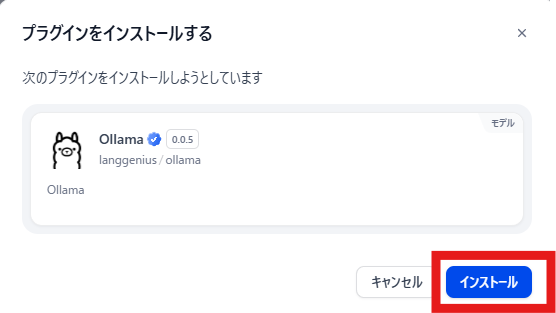
「インストール」をクリックします。
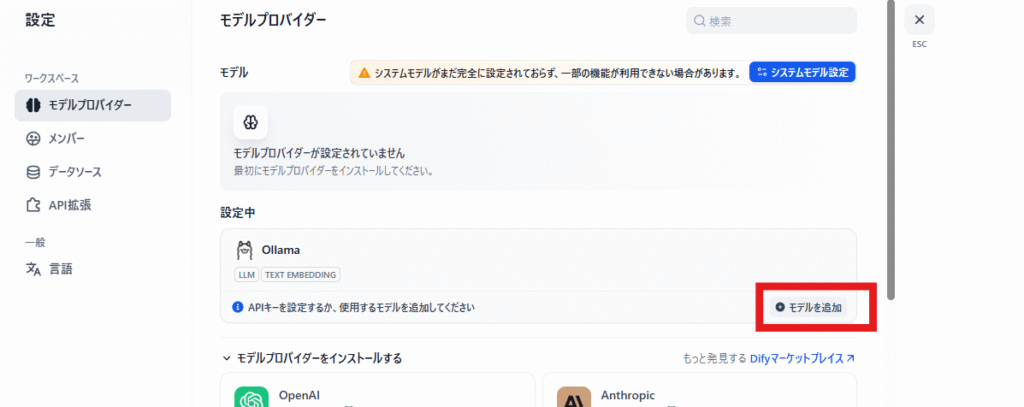
「モデルを追加」をクリックします。上図画面が表示されない場合は「モデルプロバイダー」をクリック後、モデルプロバイダーからOllamaを探し「インストール」を何度か行ってください
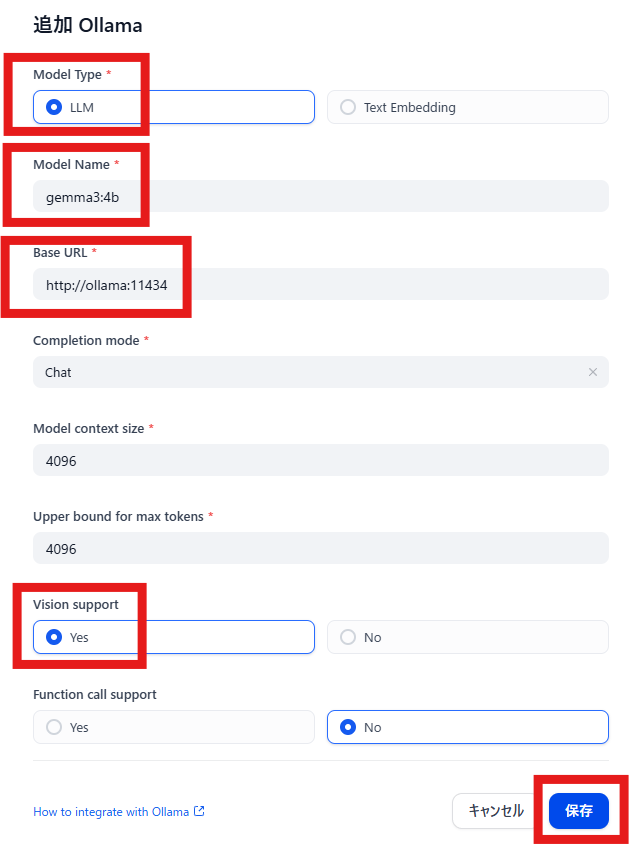
Model Typeは「LLM」を選択
Model Nameは「gemma3:4b」を指定
Base URLは「http://ollama:11434」を指定
Vision supportは「Yes」を選択
「保存」をクリックします。
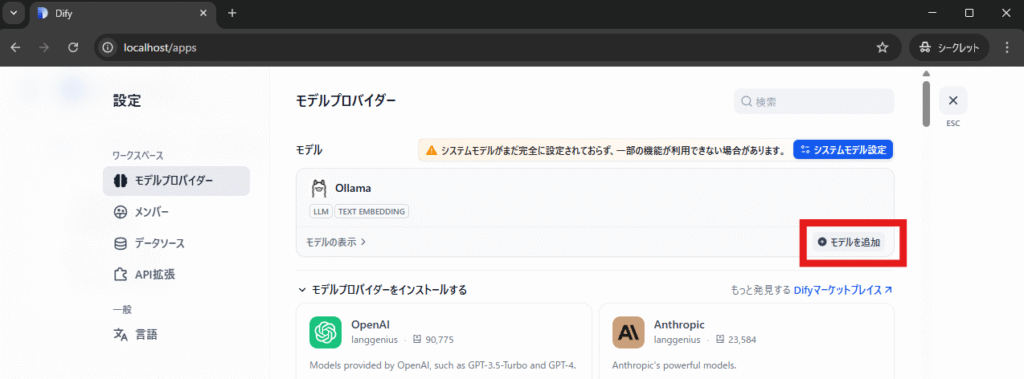
ナレッジ作成に使う埋め込みモデル(Text Embeddig)であるmxbai-embed-large:latestを追加するため「モデルを追加」をクリックします。
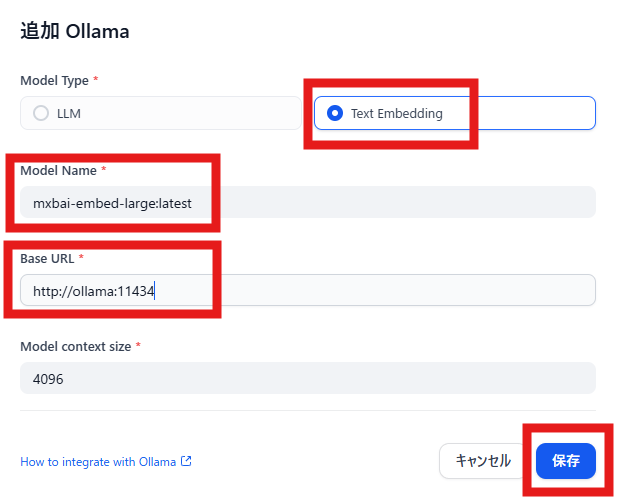
Model Typeは「Text Embedding」を選択
Model Nameは「mxbai-embed-large:latest」を指定
Base URLは「http://ollama:11434」を指定
「保存」をクリックします。
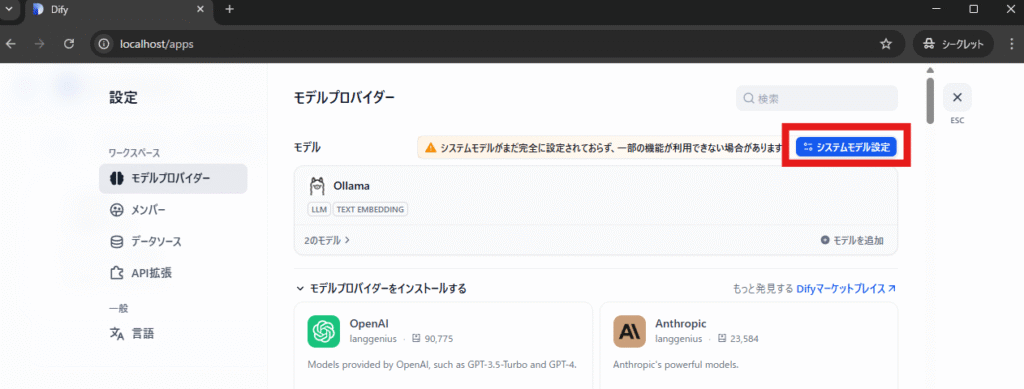
「システムモデル設定」をクリックします。
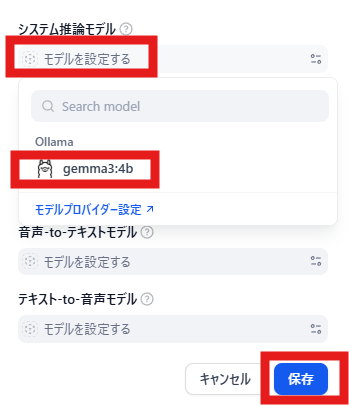
システム推論モデルの薄文字「モデルを設定する」-->「gemma3:4b」-->「保存」の順にクリックします。
「システムモデル設定」をクリックします。
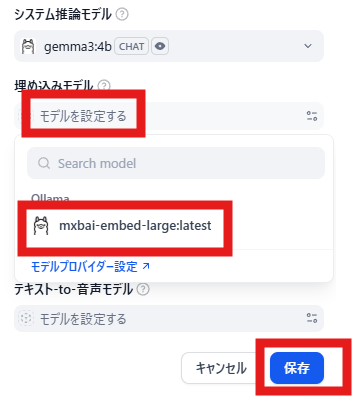
埋め込みモデルの薄文字「モデルを設定する」-->「mxbai-embed-large:latest」-->「保存」の順にクリックします。
以上でDifyでナレッジ(いわゆるRAG)を活用したチャットAIの利用が可能となりました。
少しだけ解説
DockerでOllamaを導入するコマンドとしてhttps://hub.docker.com/r/ollama/ollamaには
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
とありますが、このままですとDifyが稼働しているネットワークに属さない(接続しない)ollamaが作られてしまうのでDifyからollamaが見えないので連携できないです。ですので今回は・・・
docker run -d --restart always --network docker_default -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
のようにDifyが使っているネットワークdocker_defaultを指定しているのでhttp://ollama:11434のような指定でDifyと連携可能となりました。
次回に続く

